Experiment performance
This page describes the factors that contribute to the performance of Driverless AI experiments.
Each completed experiment iteration in Driverless AI experiments is a fitted model, but you can control the number of iterations with the time dial and the parameter_tuning_num_models TOML config mentioned in the following section. Additionally, each model takes some number of model iterations. XGBoost builds trees with a default up to about 3000 trees, but this can be modified with the max_nestimators TOML config mentioned in the following section.
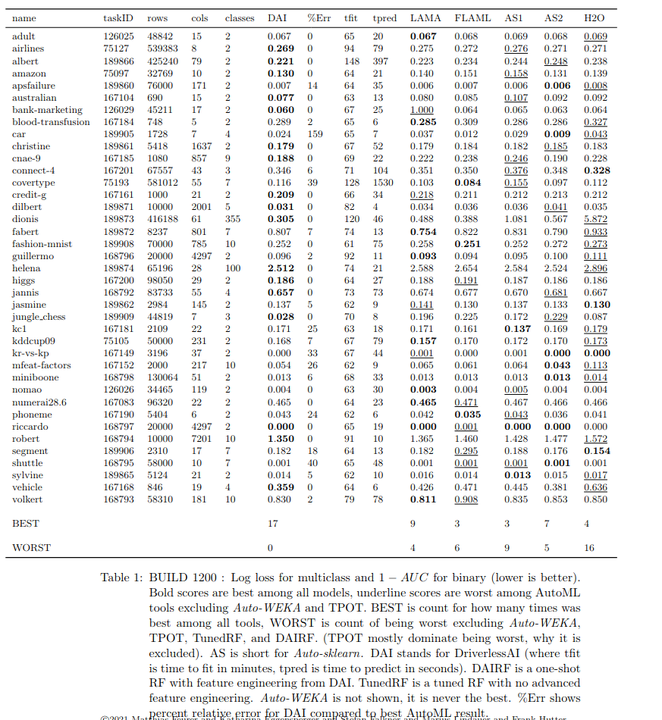
The following table presents benchmark results comparing several AutoML tools. BEST indicates the number of times each AutoML tool outperformed its competitors.
List of TOML configs that can affect performance
The following list describes a variety of controls over the experiment and model runtimes:
Set
max_runtime_minutesto a smaller number of minutes, e.g. 60 for 1 hour allowed. By default, DAI uses minimum of its estimate of an experiment runtime andmax_runtime_minutes, or greater than 1 hour as chosen bymin_auto_runtime_minutes.Some algorithms perform much better on GPUs, like XGBoost, Bert, and Image models. Using GPUs is highly recommended for XGBoost when one has several classes, when many trees are built, or data is 100k to 1M rows and 100-300 columns, or whatever would fit onto the GPU memory for larger data.
Set the
timedial to a lower value, which will do fewer models in tuning and evolution phases.Set the
interpretabilitydial to a larger value, which will more aggressively prune weak features, prune weak base models in ensemble, and avoid high-order feature interactions (interaction depth). You can also setfixed_feature_interaction_depthto control interaction depth directly.Set
parameter_tuning_num_modelsto a fixed non-zero but small value, to directly control number of tuning models instead of set automatically by dials.Set the
max_nestimatorsTOML config to a lower value (for example, 500, 1000, 1500, or 2000) instead of the default value of 3000. This controls the final model, and viamax_nestimators_feature_evolution_factor(default 0.2), controls the max for tuning and evolution models. Sometimes the data and model are such that many trees continue to learn, but the gains are minimal for the metric chosen. You can also setfixed_max_nestimatorsto directly control max independent of dials. For RF and Dart, changen_estimators_list_no_early_stoppinginstead.If the system is used by single user, set
exclusive_modetomoderate.Set
enable_early_stopping_thresholdto 0.01-0.1, which for (only) LightGBM will avoid using too many trees when evaluation metric for tree building has relative change less than this value.Set
max_abs_score_delta_train_validandmax_rel_score_delta_train_validto a non-zero value to limit the number of trees by difference between train and valid scores on metric chosen to optimize.Set
reduce_mojo_size=True. In cases where the MOJO is too large or slow, you can also set thenfeatures_maxTOML config to a value that is lower than the number of features you have. This lets you avoid too many features.Set the
min_learning_rate_finalto a higher value (for example, 0.03). You can setmax_learning_rate_finalequal tomin_learning_rate_finalto force a fixed learning rate in final model. Usemin_learning_rateandmax_learning_rateto control the learning rate for tuning and evolution models.Set
nfeatures_maxto limit the number of features. This is useful in conjuction withngenes_maxto control the maximum number of transformations (each could make 1 or more features).Set
ensemble_levelandfixed_ensemble_levelto smaller values, e.g. 0 or 1, to limit the number of base models in final model.Set
fixed_fold_repsto a smaller value, e.g. 1, to limit the number of repeats.Set
max_max_depthto a smaller value, e.g. 8, to avoid trying larger depths for tree models.Set
max_max_binto a smaller value, e.g. 128, to avoid larger max_bin values for tree models.If TensorFlow MLP model is used and reproducible is set, only 1 core is used, unless you set
tensorflow_use_all_cores_even_if_reproducible_trueto true. This loses reproducibility for the TensorFlow model, but the rest of DAI will be reproducible.
Note that the runtime estimate doesn’t take into account the number of trees needed for your data. The more trees needed by your data, the greater the amount of time needed to complete an experiment. To reduce the upper limit on the number of trees, set the max_nestimators TOML config to a value lower than 3000.
Also note that the H2O Driverless AI Experiment Setup Wizard displays comparisons of various runtime estimations and lets you specify runtime limits.
Additional information
It’s possible that your experiment has gone from using GPUs to using CPUs due to a change of the host system outside of Driverless AI’s control. You can verify this using any of the following methods:
Check GPU usage by going to your Driverless AI experiment page and clicking on the GPU USAGE tab in the lower-right quadrant of the experiment.
Run
nvidia-smiin a terminal to see if any processes are using GPU resources in an unexpected way (such as those using a large amount of memory).Check if System/GPU memory is being consumed by prior jobs or other tasks or if older jobs are still running some tasks.
Check and disable automatic NVIDIA driver updates on your system (as they can interfere with running experiments).
The general solution to these kind of sudden slowdown problems is to restart:
Restart Docker if using Docker
pkill --signal 9 h2oaiif using the native installation methodRestart the system if
nvidia-smidoes not work as expected (e.g., after a driver update)
More ML-related issues that can lead to a slow experiment are:
Choosing high accuracy settings on a system with insufficient memory
Choosing low interpretability settings (can lead to more feature engineering which can increase memory usage)
Using a dataset with a lot of columns (> 500)
Doing multi-class classification with a GBM model when there are many target classes (> 5)