Checkpointing, Rerunning, and Retraining Experiments
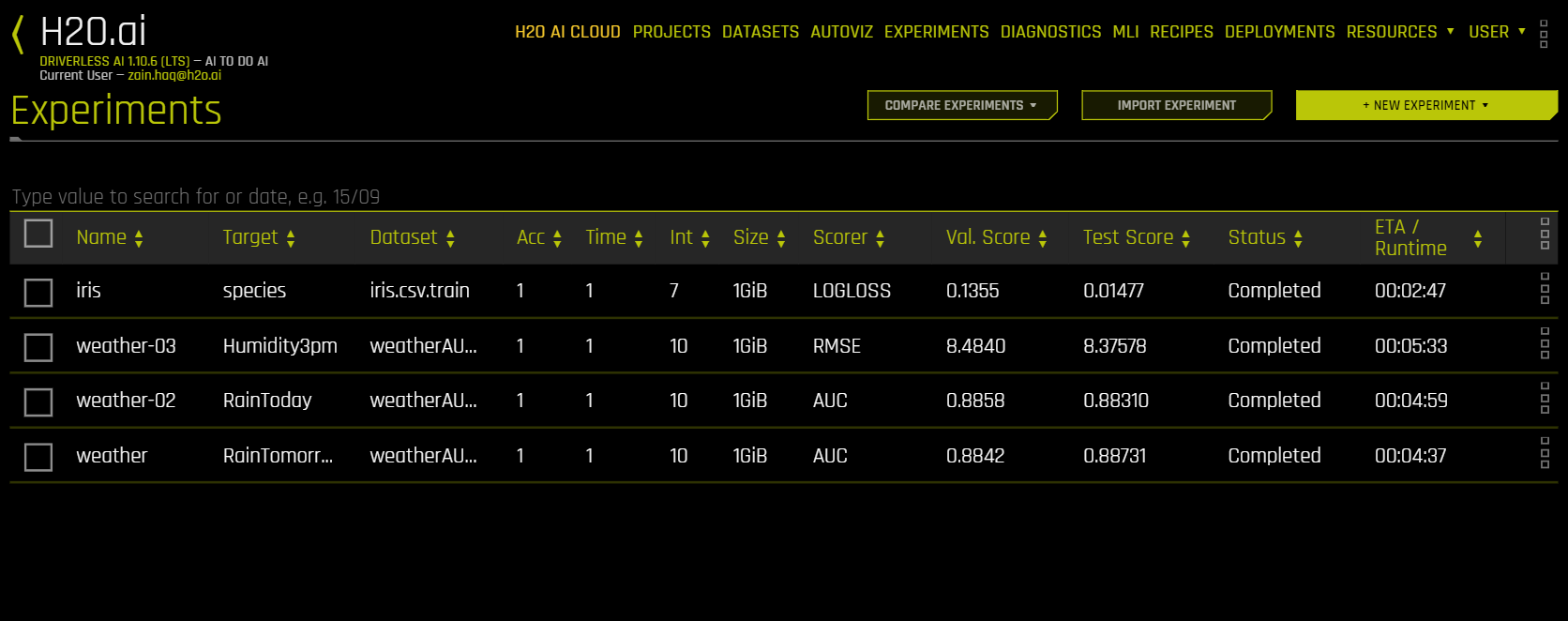
The upper-right corner of the Driverless AI UI includes an Experiments link.

Click this link to open the Experiments page. From this page, you can rename an experiment, view previous experiments, begin a new experiment, rerun an experiment, generate summaries of your experiments, and delete an experiment.
Checkpointing, Rerunning, and Retraining
In Driverless AI, you can retry an experiment from the last checkpoint, you can run a new experiment using an existing experiment’s settings, and you can retrain an experiment’s final pipeline.
Checkpointing Experiments
In real-world scenarios, data can change. For example, you may have a model currently in production that was built using 1 million records. At a later date, you may receive several hundred thousand more records. Rather than building a new model from scratch, Driverless AI includes H2O.ai Brain, which enables caching and smart re-use of prior models to generate features for new models.
You can configure one of the following Brain levels in the experiment’s Expert Settings.
-1: Don’t use any brain cache
0: Don’t use any brain cache but still write to cache
1: Smart checkpoint if an old experiment_id is passed in (for example, via running “resume one like this” in the GUI)
2: Smart checkpoint if the experiment matches all column names, column types, classes, class labels, and time series options identically. (default)
3: Smart checkpoint like level #1, but for the entire population. Tune only if the brain population is of insufficient size.
4: Smart checkpoint like level #2, but for the entire population. Tune only if the brain population is of insufficient size.
5: Smart checkpoint like level #4, but will scan over the entire brain cache of populations (starting from resumed experiment if chosen) in order to get the best scored individuals.
If you chooses Level 2 (default), then Level 1 is also done when appropriate.
To make use of smart checkpointing, be sure that the new data has:
The same data column names as the old experiment
The same data types for each column as the old experiment. (This won’t match if, for example, a column was all int and then had one string row.)
The same target as the old experiment
The same target classes (if classification) as the old experiment
For time series, all choices for intervals and gaps must be the same
When the above conditions are met, then you can:
Start the same kind of experiment, just rerun for longer.
Use a smaller or larger data set (i.e. fewer or more rows).
Effectively do a final ensemble re-fit by varying the data rows and starting an experiment with a new accuracy, time=1, and interpretability. Check the experiment preview for what the ensemble will be.
Restart/Resume a canceled, aborted, or completed experiment
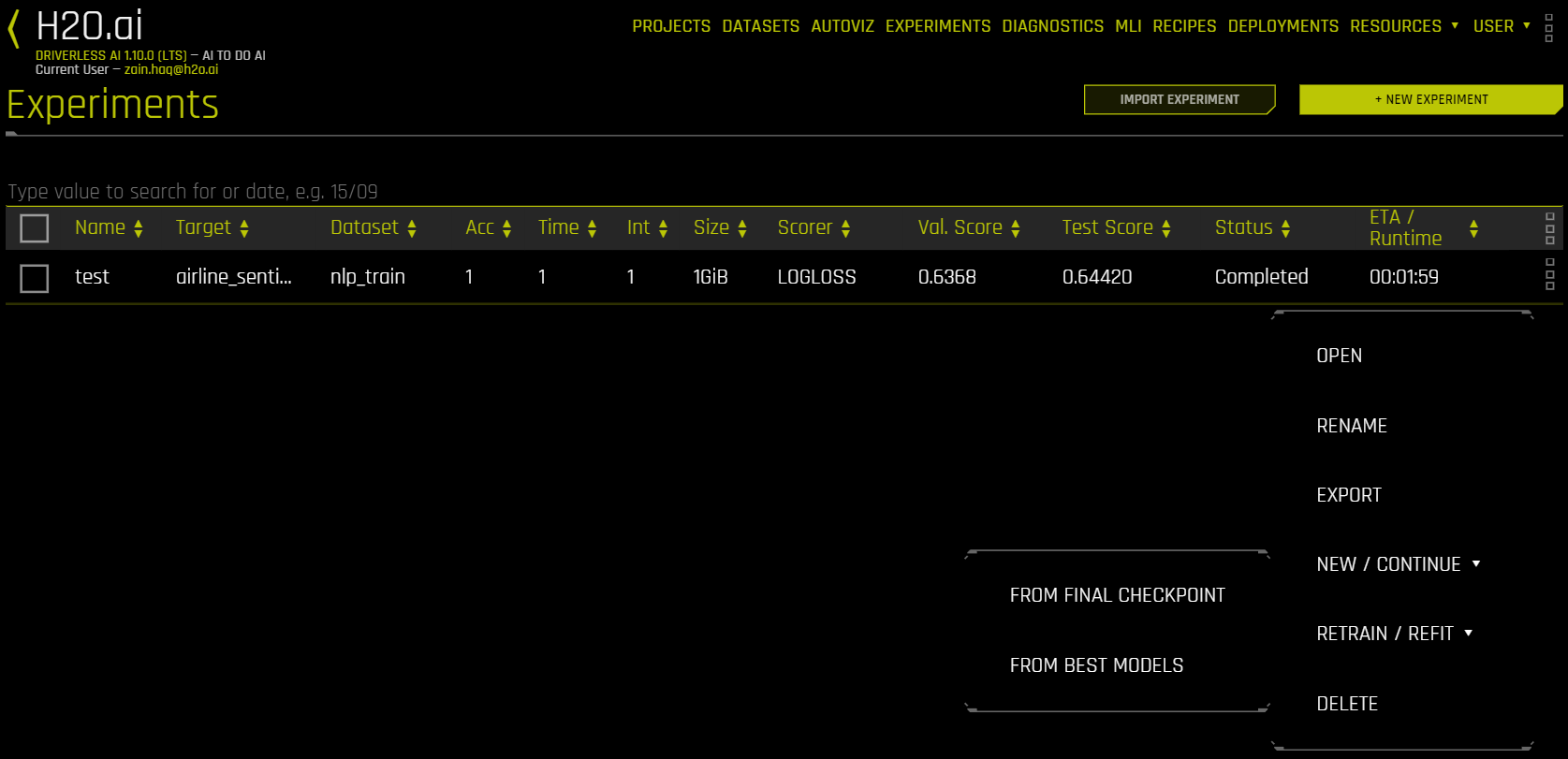
To run smart checkpointing on an existing experiment, click the right side of the experiment that you want to retry, then select New / Continue > From Last Checkpoint. The experiment settings page opens. Specify the new dataset. If desired, you can also change experiment settings, though the target column must be the same. Click Launch Experiment to resume the experiment from the last checkpoint and build a new experiment.
The smart checkpointing continues by adding a prior model as another model used during tuning. If that prior model is better (which is likely if it was run for more iterations), then that smart checkpoint model will be used during feature evolution iterations and final ensemble.
Notes:
Driverless AI does not guarantee exact continuation, only smart continuation from any last point.
The directory where the H2O.ai Brain meta model files are stored is tmp/H2O.ai_brain. In addition, the default maximum brain size is 20GB. Both the directory and the maximum size can be changed in the config.toml file.
Rerunning Experiments
To run a new experiment using an existing experiment’s settings, click the right side of the experiment that you want to use as the basis for the new experiment, then select New / Continue > With Same Settings. This opens the Experiment Setup page, from which you can rerun the experiment using the original settings, or specify to use new data and/or specify different experiment settings. Click Launch Experiment to create a new experiment with the same options.
Retrain / Refit
To retrain an experiment’s final pipeline, click on the group of square icons next to the experiment that you want to use as the basis for the new experiment and click Retrain / Refit, then select From Final Checkpoint. This opens the experiment settings page with the same settings as the original experiment except that Time is set to 0.
Note: When retraining an experiment’s final pipeline, Driverless AI also refits the experiment’s final model(s). This may include the addition of new features, the exclusion of previously used features, a change in the hyperparameter search space, or finding new parameters for the existing model architecture.
To retrain the final pipeline without adding new features, select the From Best Models option, which overrides the following config.toml options:
refit_same_best_individual=True
brain_add_features_for_new_columns=False
feature_brain_reset_score="off"
force_model_restart_to_defaults=False
For more information, refer to the feature_brain_level setting in the config.toml file.
Note
For information on the equivalent Python client calls for Retrain / Refit options, refer to the following list.
New / Continue - With Same Settings:
retrain(...)
New / Continue - From Last Checkpoint:
retrain(..., use_smart_checkpoint=True)
Retrain / Refit - From Final Checkpoint
retrain(..., final_pipeline_only=True)
Retrain / Refit - From Best Models (1.10.1 client)
retrain(..., final_models_only=True)
“Pausing” an Experiment
A trick for “pausing” an experiment is to:
Abort the experiment.
On the Experiments page, select Restart from Last Checkpoint for the aborted experiment.
On the Expert Settings page, specify 0 for the ensemble level for the final pipeline option.
Generate Experiment Results Summary
You can generate a summary of the results of an experiment by leveraging Driverless AI’s integration with h2oGPT models. For more information, see h2oGPT integration. Note that in order to use this option, you must do the following:
Enable GPT functionality by setting
enable_gpt=true.Specify your h2oGPT endpoint with the
h2ogpt_urlconfiguration option. (Note that OpenAI can also be used if you explicitly opt-in to set this configuration option to OpenAI’s API key withopenai_api_secret_key.)
For some h2oGPT URLs, specifying an h2oGPT key is required to enable authorized access for GPT-related tasks. To specify an h2oGPT key, set the
h2ogpt_keyconfiguration option.
To generate an experiment results summary, click Extra > Summarize in the list of experiment options.
Deleting Experiments
To delete an experiment, click the right side of the experiment that you want to remove, then select Delete. A confirmation message will display asking you to confirm the delete. Click OK to delete the experiment or Cancel to return to the experiments page without deleting.