Tutorial 2C: Audio regression annotation task
Overview
This tutorial describes the process of creating an audio regression annotation task, including specifying an annotation task rubric for it. To highlight the process, we will annotate a dataset containing 600 audio samples of spoken digits (0-9) of 60 different speakers.
Step 1: Explore dataset
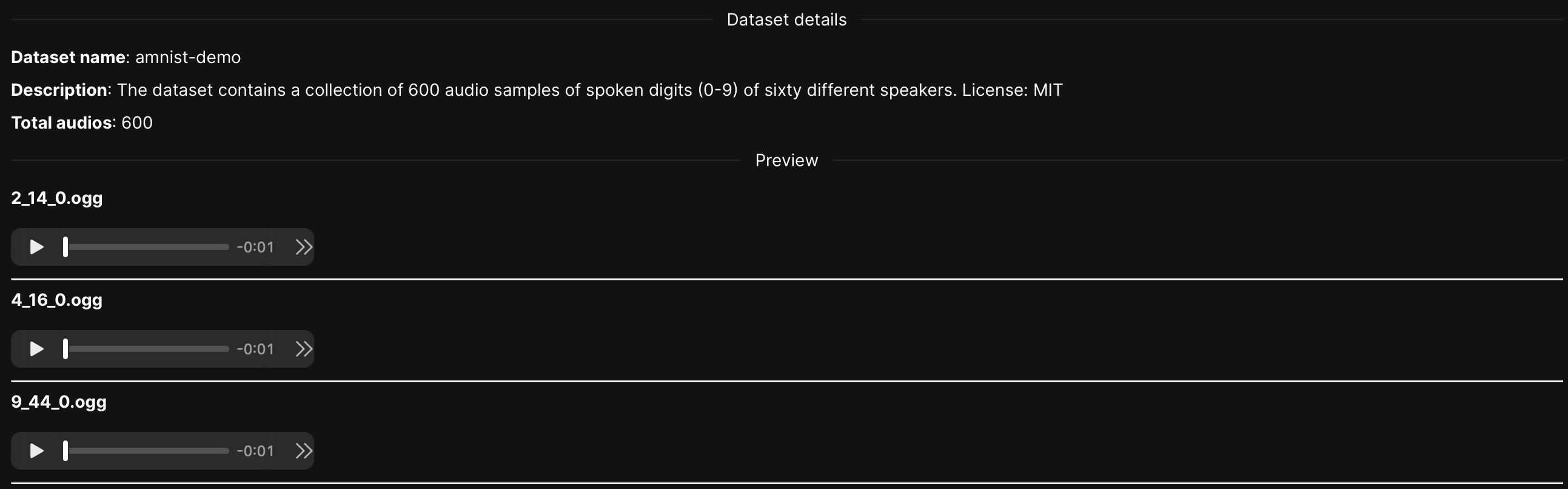
We are going to use the preloaded Amnist demo dataset for this tutorial. The dataset contains 600 samples (audio) of spoken digits (0-9) of sixty different speakers. Let's quickly explore the dataset.
- On the H2O Label Genie navigation menu, click Datasets.
- In the Datasets table, click amnist-demo.
Step 2: Create an annotation task
Now that we have seen the dataset let's create an annotation task that enables you to annotate the dataset. For this tutorial, an audio regression annotation task refers to assigning one continuous target label to each input audio.
- Click New annotation task.
- In the Task name box, enter
tutorial-2c. - In the Task description box, enter
Annotate a dataset containing samples of spoken digits (0-9) of sixty different speakers. - In the Select task list, select Regression.
- Click Create task.
Step 3: Specify an annotation task rubric
Before we can start annotating our dataset, we need to specify an annotation task rubric. An annotation task rubric refers to the labels (for example, object classes) you want to use when annotating your dataset. For our dataset, let's label each audio clip with a value from 0 to 9, where 0 refers to number 0, 1 refers to number 1, etc.
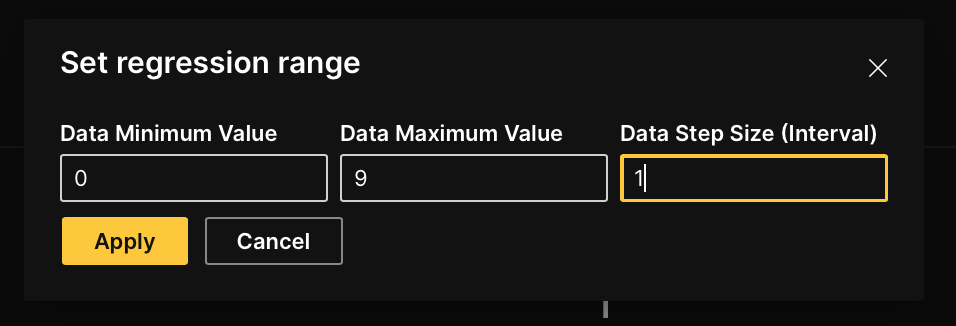
- In the Data minimum value box, enter
0.- The Data minimum value value refers to the minimum value in your continuous values (in this case, digits ranging from 0 to 9)
- In the Data maximum value box, enter
9.- The Data maximum value value refers to the maximum value in your continuous values (in this case, digits ranging from 0 to 9)
- In the Data step size (interval) box, enter
1.- The Data step size (interval) value refers to the value the label range slider interval takes (the slider its utilize in step 4)
- Click Apply
Let's utilize the slider, not the picker, to annotate the samples. To enable the slider, consider the following instructions:
- In the Annotation selection list, select Slider.

Step 4: Annotate dataset
Now that we have specified the annotation task rubric, let's annotate the dataset.
- Click Continue to annotate.
In the Annotate tab, you can individually annotate each audio clip in the dataset. Let's annotate the first audio.
- In the Label slider, slide to the label you associate with the audio sound (for example, if you hear the number 6, slide to 6).
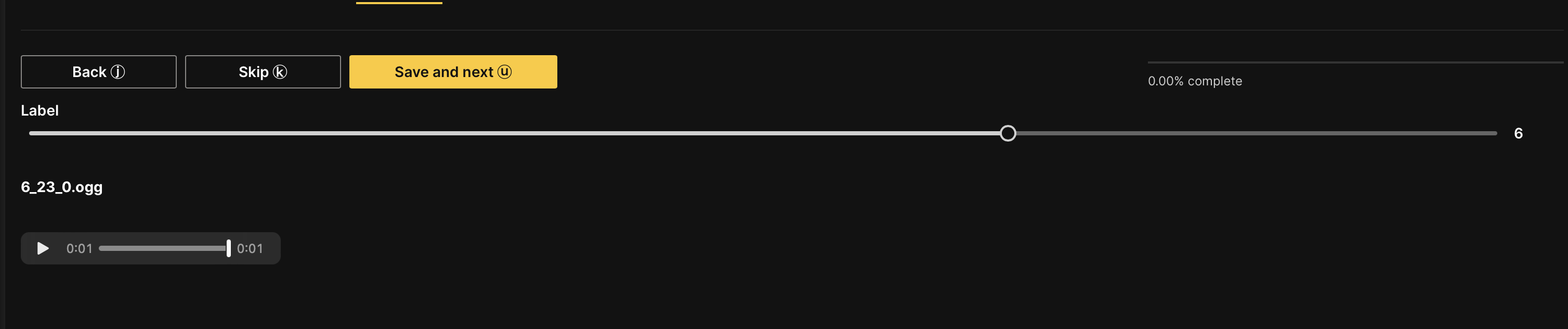
- Click Save and next.
Note
- Save and next saves the annotated audio
- To skip an audio clip to annotate later: Click Skip.
- Skipped audio clips (samples) reappear after all non-skipped audio clips are annotated
- Annotate all dataset samples.
note
At any point in an annotation task, you can download the already annotated (approved) samples. You do not need to fully annotate an imported dataset to download already annotated samples. To learn more, see Download an annotated dataset.
Summary
In this tutorial, we learned the process of annotating and specifying an annotation task rubric for an audio regression task.
Next
To learn the process of annotating and specifying an annotation task rubric for other various annotation tasks in computer vision (CV), natural language processing (NLP), and audio, see Tutorials.
- Submit and view feedback for this page
- Send feedback about H2O Label Genie to cloud-feedback@h2o.ai