새 실험¶
사용하고자 하는 교육 데이터 세트 옆에 위치한 [Click for Actions] 버튼을 선택하여 실험을 실행하십시오. 실험을 시작하려면 Predict 를 클릭합니다.
실험 설정 양식이 표시되고 선택한 데이터 세트로 자동으로 입력됩니다. 이 실험에 원하는 이름을 선택적으로 입력할 수 있습니다. 이름을 추가하지 않으면 Driverless AI가 자동으로 생성합니다.
검증 데이터 세트 및/또는 테스트 데이터 세트를 선택적으로 지정하십시오.
검증 세트는 매개변수(모델, 특성 등)의 조정에 사용됩니다. 검증 데이터 세트가 제공되지 않으면 학습 데이터를 사용합니다(홀드아웃 분할 포함). 검증 데이터 세트가 제공되면 학습 데이터는 매개변수 조정에는 사용되지 않고 학습에만 사용됩니다. 검증 데이터 세트는 데이터 분포 이동에 대한 일반화 성능의 개선에 도움을 줄 수 있습니다.
테스트 데이터 세트는 최종 단계 스코어링에 사용되며 모델 메트릭이 계산되는 데이터 세트입니다. 테스트 세트 예측은 실험 종료 시 사용할 수 있습니다. 해당 데이터 세트는 모델링 파이프라인 학습 도중에는 사용되지 않습니다.
이러한 데이터 세트에는 학습 데이터 세트와 동일한 수의 열이 있어야 함에 유의하십시오. 또한 제공되는 경우, 검증 세트가 샘플링되지 않으므로 accuracy=1(학습 크기 감소)인 경우에도 메모리 사용량이 커질 수 있습니다.
대상(응답) 열을 지정합니다. 멀티 클래스 분류 시나리오(결과가 2개 이상인 시나리오)에 대해 모든 설명 기능을 사용할 수 있는 것은 아닙니다.. 대상 열이 선택되는 경우, Driverless AI가 대상 열 유형 및 행 수를 자동으로 제공합니다. 분류 문제인 경우에는 UI가 숫자 열에 대한 고유 및 빈도 통계(Target Freq/Most Freq)를 표시합니다. 회귀 분석 문제인 경우에는 UI에 데이터 세트 평균 및 표준 편차 값이 표시됩니다.
Notes Regarding Frequency:
버전 1.0.19 이하에서 가져온 데이터의 경우 TARGET FREQ 및 MOST FREQ는 모두 숫자 대상 열에 대한 최소 빈도 클래스 수 및 범주형 대상 열에 대한 가장 빈번한 클래스 수를 나타냅니다.
버전 1.0.20~1.0.22에서 가져온 데이터의 경우, TARGET FREQ 및 MOST FREQ는 모두 이항 대상 열에 대한 대상 클래스(사전 순으로 두 번째 클래스)의 빈도를 나타냅니다. 범주형 다중 대상 열에 대한 가장 빈번한 클래스 수, 숫자 다항식 대상 열에 대한 최소 빈도 클래스 수.
버전 1.0.23 이상에서 가져온 데이터의 경우 TARGET FREQ는 이항 대상 열에 대한 대상 클래스의 빈도이고, MOST FREQ는 다중 대상 열에 대한 가장 빈번한 클래스입니다.
다음 단계는 실험에 대한 매개변수 및 설정에 대한 내용입니다.(해당 설정에 대한 자세한 내용은 Experiment Settings 섹션을 참조하십시오). 매개변수를 개별적으로 설정하거나 Driverless AI가 매개변수를 추론하도록 한 후 동의하지 않는 부분을 무시할 수 있습니다. 사용 가능한 매개변수 및 설정은 다음과 같습니다.
삭제된 열: ID 열, 데이터 유출이 있는 열 등과 같은 예측 변수로 사용하지 않는 열.
Weight Column: 행별 관측 가중치를 나타내는 열로, 《None》이 지정되면 각 행의 관측 가중치는 1이 됩니다.
Fold Column: 폴드를 나타내는 열. 《None》이 지정되면 Driverless AI에 의해 폴드가 결정됩니다. 검증 세트를 사용하는 경우 《Disabled》로 설정됩니다.
Time Column: 시간 순서를 제공하는 열(해당하는 경우). 《AUTO》가 지정되면 Driverless AI가 잠재적인 시간 순서를 자동으로 감지하고 《OFF》가 지정되면 자동 감지가 비활성화됩니다. 검증 세트를 사용하는 경우 《Disabled》로 설정됩니다.
본 실험에 사용할 Scorer 를 지정합니다. 사용 가능한 Scorer는 이것이 분류 실험인지 회귀 분석 실험인지에 따라 달라집니다. Scorer에는 다음이 포함됩니다.
회귀 분석: GINI, MAE, MAPE, MER, MSE, R2, RMSE(기본값), RMSLE, RMSPE, SMAPE, TOPDECILE
분류: ACCURACY, AUC(기본값), AUCPR, F05, F1, F2, GINI, LOGLOSS, MACROAUC, MCC
필요한 상대 accuracy를 1에서 10까지 지정하십시오.
필요한 상대 시간을 1에서 10까지 지정하십시오.
필요한 상대 해석 가능성을 1에서 10까지 지정하십시오.
Driverless AI는 accuracy, 시간 및 해석 가능성에 대한 최고의 설정을 자동으로 추론하고 이러한 제안을 기초로 실험 미리보기를 제공합니다. 이 노브를 조정하면 새로운 설정에 따라 실험 미리보기가 자동으로 업데이트됩니다.
Expert Settings (optional):
실험에 대한 추가 상세 설정을 선택적으로 지정하십시오. 해당 설정에 대한 자세한 내용은 Expert Settings 섹션을 참조하십시오. 이 옵션의 기본값은 config.toml 파일의 환경 변수에서 유래됩니다. 자세한 내용은 Setting Environment Variables 섹션을 참조하십시오.
Additional settings(optional):
Classification 또는 Regression 버튼. Driverless AI는 반응 열을 기반으로 문제 유형을 자동으로 결정합니다. 권장 사항은 아니지만, 해당 버튼을 클릭하여 이 설정을 다시 정의할 수 있습니다.
Reproducible: 이 버튼을 사용하면 무작위 시드를 사용하여 실험을 구축하고 재현 가능한 결과를 얻을 수 있습니다. 해당 옵션을 사용하지 않으면(기본값) 실행들 사이의 결과가 달라집니다.
Enable GPUs: GPU 활성화 여부를 지정하십시오(해당 옵션은 CPU 전용 시스템에서 무시됩니다).
설정이 완료되면 실험 미리보기를 검토하여 각 설정의 의미를 확인하십시오. Note: 상세 설정 를 통해 사용하는 알고리즘의 변경 시, 해당 변경 사항이 적용되지 않을 수도 있습니다. Driverless AI는 상세 설정의 계층에 따라 모델 및/또는 레시피의 포함 여부를 결정합니다. 자세한 내용은 Why do my selected algorithms not show up in the Experiment Preview? FAQ를 참조하십시오.

Launch Experiment 을 클릭하여 실험을 시작하십시오.
무작위로 생성된 실험 이름으로 실험이 시작됩니다. 해당 이름은 실험 중 또는 실험 후에 언제든지 변경이 가능합니다. 실험 이름 위에 마우스를 가져가서 수정 아이콘이 나타나면 원하는 이름을 입력합니다.
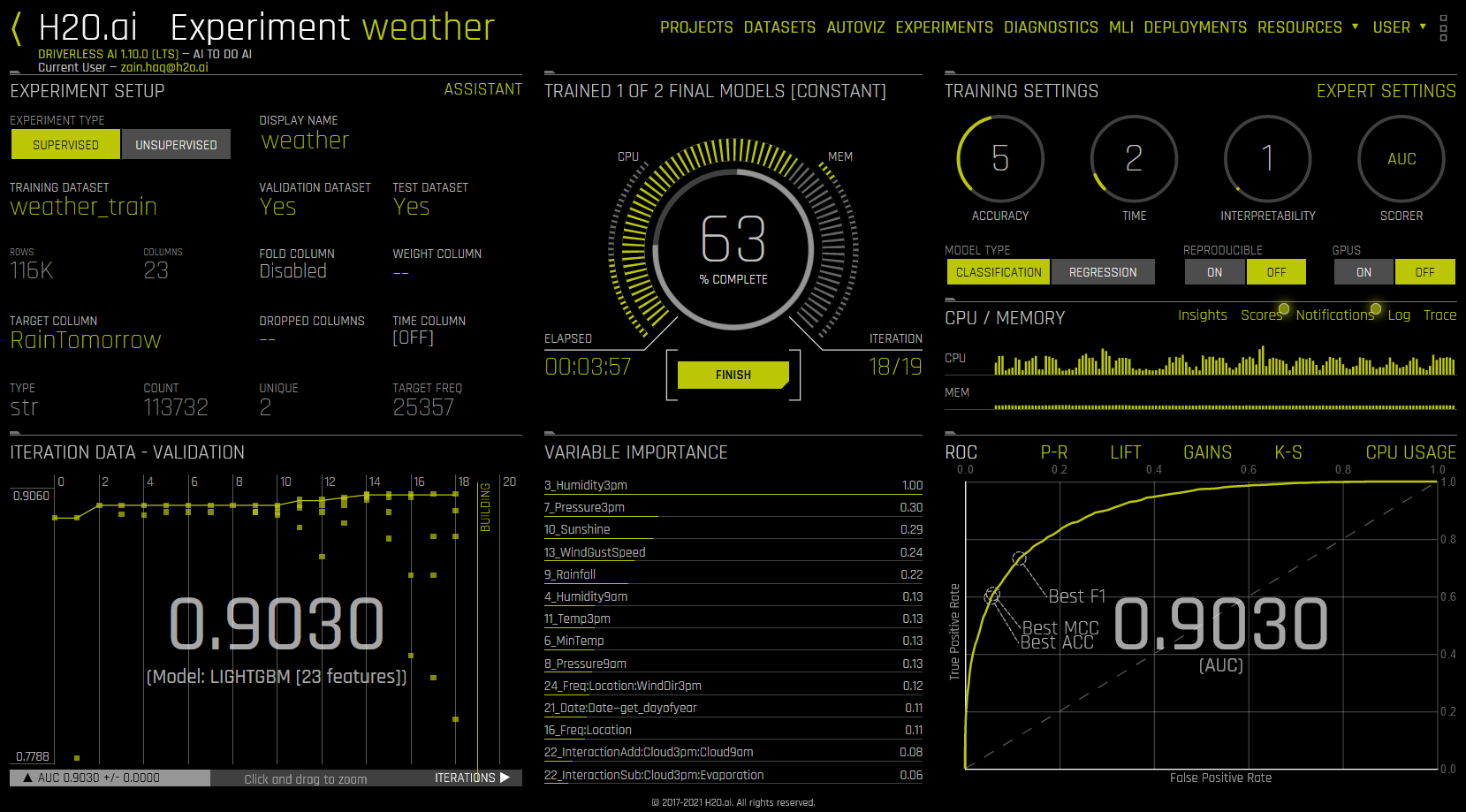
실험이 실행되면 UI의 중앙부 상단에 실행 상태가 나타납니다. 최초의 Driverless AI는 백엔드를 파악한 후 GPU의 실행 여부를 확인합니다. 그리고 매개변수 튜닝을 시작하고 변수 가공을 수행합니다. 마지막으로 Driverless AI는 스코어링 파이프라인을 구축합니다.
실험 페이지 이해¶
상태 외에도, 실험이 실행 중이면 UI에 다음이 표시됩니다.
데이터 세트 세부 내용
지정된 scorer 값을 사용한 각각의 교차 검증 폴더에 대한 반복 데이터(내부 검증)입니다. 특정 반복을 클릭하거나 드래그하여 반복 범위를 확인하십시오. 보기를 재설정하려면 그래프를 두 번 클릭합니다. 해당 그래프에서 각 《column》은 실험의 하나의 반복을 나타냅니다. 반복하는 도중에 Driverless AI는 \(n\) 모델을 학습시킵니다(실험 미리보기에서는 개체라고 불림). 따라서 모든 열에 대해 그래프의 각각의 반복에 대한 해당 \(n\) 모델의 점수 값을 확인할 수 있습니다.
가변 중요도 값. 특정 반복에 대한 변수 중요도를 확인하려면 반복 데이터 그래프에서 해당 반복을 선택하면 됩니다. 변수 중요도 목록은 해당 반복에 대한 변수 중요도 정보를 표시하도록 자동으로 업데이트됩니다. 자세한 정보를 확인하려면 항목 위로 마우스 커서를 가져가면 됩니다.
Notes:
변환된 특성 이름은 다음과 같이 인코딩됩니다.
<transformation/gene_details_id>_<transformation_name>:<orig>:<…>:<orig>.<extra>
따라서
32_NumToCatTE:BILL_AMT1:EDUCATION:MARRIAGE:SEX.0에서, 예를 들면 다음과 같습니다.
32_는 특정 변환 매개변수에 대한 변환 지수입니다.
NumToCatTE는 변환 유형입니다.
BILL_AMT1:EDUCATION:MARRIAGE:SEX는 원래 사용된 특성을 나타냅니다.
0은 특성(여기서는BILL_AMT1,EDUCATION,MARRIAGE및SEX로 표시됨)별로 그룹화하고 폴드 외 추정을 만든 후 대상[0]에 대한 가능한 인코딩을 나타냅니다. 멀티 클래스 실험의 경우, 이 값은 0보다 큽니다. 이진 실험의 경우, 이 값은 항상 0입니다.
항목 위로 마우스 커서를 가져가면 《Internal[…] specification.” 이라는 용어가 표시됩니다. 해당 레이블은 번역/설명할 필요가 없는 특성에 사용되며 모든 특성이 고유하게 식별되도록 합니다.
표시되는 값은 모델 클래스의 변수 중요도에 따라 다릅니다.
XGBoost 및 LightGBM: 다양한 중요성을 얻습니다. 이득 기반 중요도는 특정 변수가 모델에 가져오는 이득으로부터 계산됩니다. decision tree의 경우 이득 기반 중요도는 데이터가 주어진 변수에 의해 분할될 때마다 발생한 이득을 합산합니다. 이득 기반 중요도는 0과 1 사이에서 정규화됩니다. 변수가 모델에서 사용되지 않는 경우, 이득 기반 중요도는 0이 됩니다.
GLM: 변수 중요도는 각 예측 변수에 대한 계수의 절댓값입니다. 변수 중요도는 0과 1 사이에서 정규화됩니다. 변수가 모델에서 사용되지 않는 경우 해당 중요도는 0이 됩니다.
TensorFlow: TensorFlow는 이 문서: https://www.ncbi.nlm.nih.gov/pubmed/9327276 에 설명된 Gedeon 방법을 따릅니다.
RuleFit: 각 규칙에 대한 기능의 기여도에 대한 합계입니다. 특히, Driverless AI:
중요도가 0인 모든 특성을 할당하십시오.
모든 규칙을 스캔합니다. 특성이 해당 규칙에 포함된 경우 Driverless AI는 전체 특성 중요도에 기여도(즉, 규칙 계수의 절댓값)를 추가합니다.
중요도 정규화
변수 중요도의 이동에 대한 계산은 앙상블 레벨에 의해 결정됩니다.
앙상블 레벨 = 0: 마지막 최상 유전 알고리즘(GA) 및 단일 최종 모델 사이의 이동이 결정됩니다.
앙상블 레벨>= 1: 최종 모델에 사용된 GA 개체는 모델의 메타 러너 가중치와 혼합된 가변 중요도를 가지며 최종 모델 자체는 최종 가중치와 혼합된 가변 중요도를 갖습니다. 변수 중요도의 이동은 이 두 가지 최종 변수 중요도 혼합 사이에서 결정됩니다.
이 정보는 만약 해당 이동이
max_num_varimp_shift_to_log구성 옵션에 지정된 절대 크기를 초과하는 경우 로그 또는 GUI에 보고됩니다. 실험 요약은 이동에 대한 정보를 포함한 experiment_features_shift 파일을 포함하고 있습니다.
Insights (time series 실험용), Scores, 알림, 로그 및 추적 정보를 포함한 CPU/메모리 정보(Trace는 개발/ 디버깅에 사용되며, 해당 순간 시스템이 무엇을 하고 있는지 나타냅니다).
분류 문제의 경우, 우측 하단 섹션에는 ROC 곡선, Precision-Recall 그래프, 향상도 차트, 이득 차트 및 GPU 사용량 정보(GPU를 사용할 수 있는 경우) 사이의 전환이 포함되어 있습니다. 회귀 분석 문제의 경우 우측 하단 섹션에는 잔차 차트, 실제 대 예측 차트 및 GPU 사용량 정보(GPU를 사용할 수 있는 경우) 사이의 전환이 포함되어 있습니다.(자세한 내용은 Experiment Graphs 섹션을 참조하십시오.) 완료 시, 실험 요약 섹션이 우측 하단 섹션에 채워집니다.
실험 화면의 하단에는 Driverless AI가 직면하는 모든 경고가 표시됩니다. x 아이콘을 클릭하여 해당 창을 숨길 수 있습니다.
실험 종료/중단¶
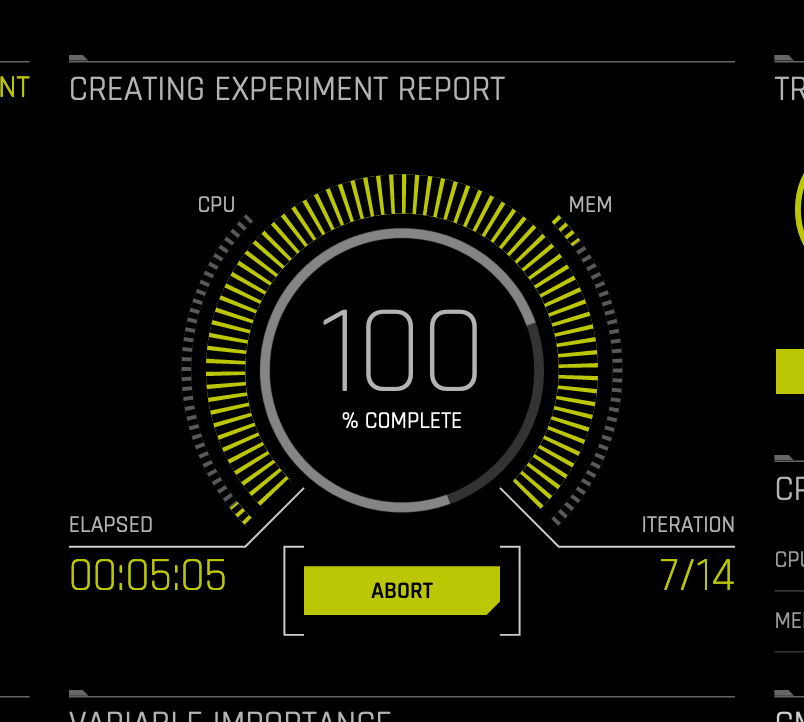
현재 실행 중인 실험을 완료 및/또는 중단할 수 있습니다.
Finish 실행 중인 실험을 중지하려면 Finish 버튼을 클릭하십시오. Driverless AI가 실험을 종료하고 앙상블링 및 배포 패키지를 완료합니다.
Abort: Finish 을 클릭한 후, Abort 을 클릭하여 실험을 종료할 수 있습니다(중단을 확인하라는 메시지가 나타납니다). 중단된 실험은 실험 페이지에 실패로 표시됩니다. 실험의 우측을 클릭한 후, Restart from Last Checkpoint 를 선택하여 중단된 실험을 다시 시작할 수 있습니다. 중단된 실험을 기초로 새로운 실험이 시작됩니다. 또는, New Experiment with Same Settings 을 선택하여 중단된 실험을 기반으로 새 실험을 시작할 수 있습니다. 자세한 내용은 Checkpointing, Rerunning, and Retraining 를 참조하십시오.
《Pausing》 실험¶
실험을 《pausing》하는 요령은 다음과 같습니다.
실험을 중단합니다.
실험 페이지에서 중단된 실험에 대해 Restart from Last Checkpoint 을 선택합니다.
Expert Settings 페이지에서 새 실험의 Expert Settings. 에 있는 Ensemble level for final modeling pipeline 옵션에 0을 지정합니다.