Scorer¶
분류 또는 회귀 분석¶
GINI(Gini Coefficient)¶
Gini 지수는 도수 분포(frequency distribution) 값 간의 불평등을 정량화하는 확실한 방법으로, 바이너리 분류기의 품질을 측정하는 데 사용할 수 있습니다. Gini 지수가 0이면 완전한 평등(또는 전혀 유용하지 않은 분류기)을 나타내고, Gini 지수가 1이면 최대 불평등(또는 완벽한 분류기)을 나타냅니다.
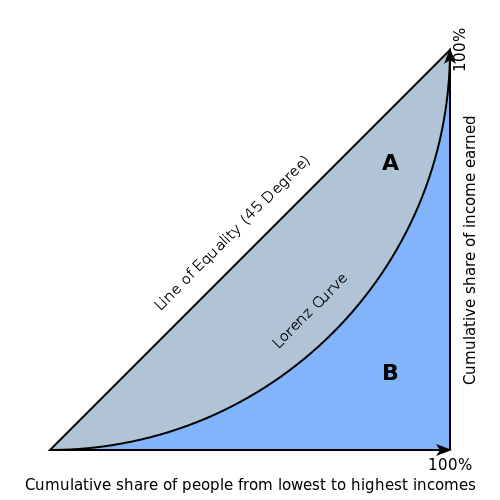
Gini 지수는 로렌츠 곡선(Lorenz curve)을 기반으로 합니다. 로렌츠 곡선은 모집단(x축)의 백분위 수 함수로 True Positive 비율(y축)을 표시합니다.
로렌츠 곡선은 분류기(classifier)에 의해 표시되는 모델의 집합을 나타냅니다. 곡선의 위치는 특정 모델의 확률 임계값으로 정해집니다(즉, 분류에 대한 확률 임계값이 낮을수록 일반적으로 True Positive가 많아지지만, False Positive도 많아집니다).
Gini 지수 자체는 모델과는 독립적이며, 분류기에서 얻은 점수(또는 확률) 분포로 결정되는 로렌츠 곡선만을 기반으로 계산합니다.
회귀 분석¶
R2(R Squared)¶
R2(결정 계수) 값은 예측값과 실제값이 함께 움직이는 정도를 나타냅니다. R2 값의 범위는 0과 1 사이이며, 0은 예측값과 실제값 사이의 상관 관계가 없음을 나타내고 1은 완전한 상관 관계를 나타냅니다.
선형 모델에 대한 R2 값 계산은 수학적으로 \(1 - SSE/SST\) 과 같습니다(또는 \(1 - \text{잔차 제곱의 합}/\text{총 제곱의 합}\)). 기타 모든 모델의 경우 이 등가가 유지되지 않으므로, \(1 - SSE/SST\) 공식을 사용할 수 없습니다. 어떤 경우에는, 이 공식에서 마이너스 R2 값이 나올 수 있으며 이는 수학적으로 실수가 될 수 없습니다. Driverless AI는 반드시 선형 모델을 사용할 필요는 없으므로, 피어슨 상관계수(Pearson correlation coefficient)의 제곱을 사용하여 R2 값을 계산합니다.
R2 방정식:
여기서,
x는 예측된 목표값입니다.
y는 실제 목표값입니다.
MSE(Mean Squared Error)¶
MSE 메트릭은 오차 또는 편차의 제곱의 평균을 측정합니다. MSE는 점에서 회귀선까지의 거리(이 거리가 ‘오차’임)를 제곱하여 음의 부호를 제거합니다. MSE는 예측 변수의 분산(variance)과 편향(bias)을 모두 통합합니다.
또한, MSE는 차이가 클수록 더 높은 가중치를 부여합니다. 오차가 클수록 벌점을 더 많이 부과합니다. 예를 들어, 정답이 2,3,4이고 알고리즘이 1,4,3을 추정하는 경우, 각 값의 절대 오차는 정확히 1이므로 오차의 제곱도 1이고 MSE는 1입니다. 그러나, 알고리즘이 2,3,6을 추정하면 오차가 0,0,2이고 오차의 제곱은 0,0,4가 되며, MSE는 더 높은 1.333입니다. MSE가 작을수록 모델의 성능이 높습니다( 팁: MSE는 outliers에 민감합니다. 덜 민감한(robust) 메트릭을 원하면 평균 절대 오차(MAE)를 사용하십시오).
MSE 방정식:
RMSE (Root Mean Squared Error)¶
RMSE 메트릭은 모델이 연속 값을 얼마나 잘 예측할 수 있는지 평가합니다. RMSE 단위는 예측된 목표와 동일하므로 오차의 크기가 중요한지 여부를 파악하는 데 유용합니다. RMSE가 작을수록 모델의 성능이 우수합니다( Tip: RMSE는 outliers에 민감합니다. 덜 민감한(robust) 메트릭을 원하면 평균 절대 오차(MAE)를 사용하십시오).
RMSE 방정식:
여기서,
N 는 해당 데이터 프레임의 총 행(관측치)의 수입니다.
y 는 실제 목표값입니다.
\(\hat{y}\) 는 예측된 목표값입니다.
RMSLE(Root Mean Squared Logarithmic Error)¶
이 메트릭은 실제값과 예측값 사이의 비율을 측정하고 예측값과 실제값의 로그를 사용합니다. 과소 예측보다는 과대 예측이 더 나은 경우, RMSE 대신 이 메트릭을 사용하십시오. 두 값이 모두 크고 큰 차이에 벌점을 적용하지 않으려는 경우에도 사용할 수 있습니다.
RMSLE 방정식:
여기서,
N 는 해당 데이터 프레임의 총 행(관측치)의 수입니다.
y 는 실제 목표값입니다.
\(\hat{y}\) 는 예측된 목표값입니다.
RMSPE (Root Mean Square Percentage Error)¶
이 메트릭은 백분율로 표현되는 RMSE입니다. RMSPE가 작을수록 모델 성능이 우수합니다.
RMSPE 방정식:
MAE (Mean Absolute Error)¶
평균 절대 오차(MAE)는 절대 오차의 평균입니다. MAE 단위는 예측된 목표와 동일하므로 오차의 크기가 중요한지 여부를 이해하는 데 유용합니다. MAE가 작을수록 모델의 성능이 우수합니다( Tip: MAE는 outliers에 강건(robust)합니다. outliers에 민감한 메트릭을 원하면 RMSE(Root Mean Squared Error)를 사용하십시오).
MAE 방정식:
여기서,
N 은 총 오차의 개수입니다.
\(| x_i - x |\) 는 절대 오차와 같습니다.
MAPE (Mean Absolute Percentage Error)¶
MAPE는 오차의 크기를 백분율로 측정합니다. 부호 없는 백분율 오차의 평균으로 계산합니다.
MAPE 방정식:
MAPE 측정값은 백분율로 표시되기 때문에, 서로 다른 척도 간의 오차의 크기를 확인할 수 있습니다. 다음 예를 참조하십시오.
실제값 |
예측값 |
절대 오차 |
절대 백분율 오차 |
|---|---|---|---|
5 |
1 |
4 |
80% |
15,000 |
15,004 |
4 |
0.03% |
두 레코드 모두 절대 오차가 4이지만, 실제값과 비교하면 이 오차를 《작다》 또는 《크다》 고 평가할 수 있습니다.
SMAPE(Symmetric Mean Absolute Percentage Error)¶
절대 오차를 절대 실제값으로 나누는 MAPE와 달리, SMAPE는 절대 실제값과 절대 예측값의 평균으로 나눕니다. 이는 실제값이 0 또는 0에 가까울 때 중요합니다. 실제값이 0에 가까우면 MAPE 값이 무한히 높아집니다. SMAPE에는 실제값과 예측값이 모두 포함되므로, SMAPE 값은 200%를 초과할 수 없습니다.
다음 예를 참조하십시오.
실제값 |
예측값 |
|---|---|
0.01 |
0.05 |
0.03 |
0.04 |
이 데이터에서 MAPE는 216.67%인데, SMAPE는 80.95%에 불과합니다.
두 레코드 모두 절대 오차가 4이지만, 실제값과 비교하면 이 오차를 《작다》 또는 《크다》 고 평가할 수 있습니다.
MER(Median Error Rate or Median Absolute Percentage Error)¶
MER은 오차의 중위 크기를 백분율로 측정합니다. 부호 없는 백분율 오차의 중앙값(median)으로 계산합니다.
MER 방정식:
MER은 중앙값이므로, 채점된 모집단의 절반은 MER보다 절대 백분율 오차가 낮고 모집단의 절반은 MER보다 절대 백분율 오차가 더 큽니다.
분류¶
MCC(Matthews Correlation Coefficient)¶
MCC 메트릭의 목표는 모델의 혼동 행렬(confusion matrix)을 단일 숫자로 나타내는 것입니다. MCC 메트릭은 아래에 나와 있는 방정식을 사용하여 True Positive, False Positive, True Negative, False Negative를 조합합니다.
Driverless AI 모델은 예측된 클래스가 아니라 확률을 반환합니다. 확률을 예측 클래스로 변환하려면, 임계값을 정의해야 합니다. Driverless AI는 가능한 임계값을 반복하여 각 임계값에 대한 혼동 행렬을 계산합니다. 이렇게 하여 최대 MCC 값을 찾습니다. Driverless AI의 목표는 이 최대 MCC를 계속 증가시키는 것입니다.
accuracy 등의 메트릭과 달리, MCC는 목표 변수가 불균형할 때 사용하기에 좋은 scorer입니다. 불균형 데이터의 경우 다수 클래스(majority class)를 예측하여 높은 accuracy를 찾을 수 있습니다. accuracy 및 F1과 같은 메트릭은 특히 불균형 데이터에 대해 네 가지 혼동 행렬 범주의 상대적 크기를 고려하지 않기 때문에 오해를 줄 수 있습니다. 그러나 MCC는 각 클래스의 비율을 고려합니다. MCC 값의 범위는 -1에서 1이며, 여기서 -1은 실제값에 반대되는 클래스를 예측하는 분류기를 나타내고, 0은 분류기가 무작위 추정과 비슷함을 의미하며, 1은 완벽한 분류기를 나타냅니다.
MCC 방정식:
F05, F1, 및 F2¶
Driverless AI 모델은 예측된 클래스가 아니라 확률을 반환합니다. 확률을 예측 클래스로 변환하려면, 임계값을 정의해야 합니다. Driverless AI는 가능한 임계값을 반복하여 각 임계값에 대한 혼동 행렬을 계산합니다. 이렇게 하여 최대 F 메트릭 값을 찾습니다. Driverless AI의 목표는 이 최대 F 메트릭을 계속 증가시키는 것입니다.
F1 점수는 바이너리 분류기가 양성(Positive) 사례를 얼마나 잘 분류하는지에 대한 측정값을 제공합니다(임계값이 주어졌을 때). F1 점수는 정밀도와 재현율의 조화 평균으로 계산합니다. F1 점수가 1이면 정밀도와 재현율이 모두 완벽하고 모델이 모든 양성 사례를 올바르게 식별하며 음성(Negative) 사례를 양성 사례로 표시하지 않았음을 의미합니다. 정밀도 또는 재현율이 아주 낮으면, F1 점수가 0에 가깝습니다.
F1 방정식:
여기서,
Precision 은 모델이 양성으로 분류한 모든 관측치(True Positive + False Positive) 중에서 올바르게 식별한 양성 관측치(True Positive)입니다.
Recall 은 실제 양성 사례(True Positive + False Negative) 중에서 모델이 올바르게 식별한 양성 관측치(True Positive)입니다.
F0.5 점수는 정밀도 및 재현율의 가중 조화 평균입니다(임계값이 주어졌을 때). 정밀도와 재현율에 동일한 가중치를 부여하는 F1 점수와 달리, F0.5 점수는 재현율보다 정밀도에 더 많은 가중치를 부여합니다. False Positive보다 False Negative이 더 나은 경우, 사례의 정밀도에 더 많은 가중치를 부여해야 합니다. 예를 들어, 사용 사례를 통해 어떤 제품이 품절될지 예측해야 할 경우, False Positive가 False Negative보다 더 부적합한 것으로 간주할 수 있습니다. 이런 경우 매우 정확하고 확실하게 품절될 제품만 캡처할 수 있는 예측이 필요합니다. 실제로는 필요 없는데 제품을 재입고해야 할 것으로 예측하는 경우, 실제 필요한 재고보다 많이 구매하게 되어 비용이 발생합니다.
F05 방정식:
여기서,
Precision 은 모델이 양성으로 분류한 모든 관측치(True Positive + False Positive) 중에서 올바르게 식별한 양성 관측치(True Positive)입니다.
Recall 은 실제 양성 사례(True Positive + False Negative) 중에서 모델이 올바르게 식별한 양성 관측치(True Positive)입니다.
F2 점수는 정밀도 및 재현율의 가중 조화 평균입니다(임계값이 주어졌을 때). 정밀도와 재현율에 동일한 가중치를 부여하는 F1 점수와 달리, F2 점수는 정밀도보다 재현율에 더 많은 가중치를 부여합니다. False Negative보다 False Positive가 더 나은 경우, 사례의 재현율에 더 많은 가중치를 부여해야 합니다. 예를 들어, 사용 사례를 통해 이탈할 고객을 예측해야 할 경우, False Negative가 False Positive보다 더 부적합한 것으로 간주할 수 있습니다. 이런 경우 이탈할 모든 고객을 캡처할 수 있는 예측이 필요합니다. 이러한 고객 중 일부는 이탈할 위험이 없을 수도 있지만, 주의를 더 기울이는 것이 나쁘지는 않습니다. 더 중요한 것은 실제 이탈 가능성이 있는 고객을 놓치지 않는 것입니다.
F2 방정식:
여기서,
Precision 은 모델이 양성으로 분류한 모든 관측치(True Positive + False Positive) 중에서 올바르게 식별한 양성 관측치(True Positive)입니다.
Recall 은 실제 양성 사례(True Positive + False Negative) 중에서 모델이 올바르게 식별한 양성 관측치(True Positive)입니다.
Accuracy¶
바이너리 분류에서, accuracy는 올바른 예측의 수를 전체 예측 비율로 나타낸 것입니다. 다중 클래스 분류에서 샘플에 대해 예측된 레이블 집합은 그에 상응하는 y_true 레이블 집합과 정확하게 일치해야 합니다.
Driverless AI 모델은 예측된 클래스가 아니라 확률을 반환합니다. 확률을 예측 클래스로 변환하려면, 임계값을 정의해야 합니다. Driverless AI는 가능한 임계값을 반복하여 각 임계값에 대한 혼동 행렬을 계산합니다. 이렇게 하여 최대 accuracy 값을 찾습니다. Driverless AI의 목표는 이 최대 accuracy를 계속 증가시키는 것입니다.
accuracy 방정식:
Logloss¶
Logloss(Logarithmic loss) 메트릭은 이항 또는 다항 분류기의 성능을 평가하는 데 사용할 수 있습니다. 모델이 바이너리 타겟을 분류하는 성능을 평가하는 AUC와 달리, Logloss는 모델의 예측값(보정되지 않은 확률 추정치)이 실제 목표값에 얼마나 근사한지 평가합니다. 예를 들어, 모델이 양성 클래스에 대해 0.80과 같이 높은 예측값을 할당하는 경향이 있는가, 또는 양성 클래스를 인식하는 능력이 부족하여 0.50 정도의 낮은 예측값을 할당하는가를 평가합니다. Logloss는 0 이상의 어떤 값이나 될 수 있으며, 0은 모델이 0% 또는 100%의 확률을 올바르게 할당함을 의미합니다.
바이너리 분류 방정식:
다중 클래스 분류 방정식:
여기서,
N 는 해당 데이터 프레임의 총 행(관측치)의 수입니다.
w 는 행별 사용자 정의 가중치입니다(기본값 1).
C 는 총 클래스 수입니다(바이너리 분류의 경우 C = 2).
p 는 주어진 행(관측치)에 할당된 예측값(보정되지 않은 확률)입니다.
y 는 실제 목표값입니다.
AUC (Area Under the Receiver Operating Characteristic Curve)¶
이 모델 메트릭은 바이너리 분류 모델이 True Positive와 False Positive를 구별하는 성능을 평가하는 데 사용됩니다. 다중 클래스 문제의 경우 이 점수는 각 클래스의 ROC 곡선을 마이크로 평균하여 계산합니다. 매크로 평균을 선호하는 경우 MACROAUC를 사용하십시오.
AUC가 1이면 완벽한 분류기를 나타내고, AUC가 0.5이면 성능이 무작위 추정이나 다를 바 없는 부적절한 분류기를 나타냅니다.
AUCPR(Area Under the Precision-Recall Curve)¶
이 모델 메트릭은 바이너리 분류 모델이 정밀도-재현율 쌍 또는 포인트를 구별하는 성능을 평가하는 데 사용됩니다. 이 값은 확률 또는 다른 연속 출력 분류기에서 다양한 임계값을 사용하여 얻습니다. AUCPR은 주어진 임계값의 확률에 의해 가중된 정밀도-재현율의 평균입니다.
AUC와 AUCPR의 주요 차이점은 AUC는 ROC 곡선 아래의 영역을 계산하고, AUCPR은 Precision Recall 곡선 아래의 영역을 계산하는 것입니다. Precision Recall 곡선에서는 True Negative가 고려되지 않습니다. 불균형 데이터의 경우, 대량의 True Negative가 일반적으로 False Positive 등 다른 메트릭의 변경으로 인한 영향보다 중요합니다. AUCPR은 AUC보다 True Positive, False Positive, False Negative에 훨씬 더 민감합니다. 따라서 불균형이 심한 데이터의 경우 AUC보다는 AUCPR을 권장합니다.
MACROAUC(Macro Average of Areas Under the Receiver Operating Characteristic Curves)¶
다중 클래스 분류 문제의 경우, 이 점수는 각 클래스에 대한 ROC 곡선을 매크로 평균하여 계산됩니다(클래스당 하나). 곡선 아래의 영역은 상수입니다. MACROAUC가 1이면 완벽한 분류기를 나타내고, MACROAUC가 0.5이면 성능이 무작위 추정이나 다를 바 없는 부적절한 분류기를 나타냅니다. 이 옵션은 바이너리 분류 문제에는 사용할 수 없습니다.
scorer 모범 사례 - 회귀 분석¶
회귀분석 문제에 사용할 scorer를 결정할 때는 다음을 고려합니다.
outliers에 민감한 scorer가 필요한가?
scorer의 단위는?
Outliers에 대한 민감도
특정 scorer는 outliers에 더 민감합니다. scorer가 outliers에 민감한 경우, 모델 예측이 너무 부정확하지는 않도록 해야 합니다. 예를 들어 이벤트 발생까지의 일수를 예측하는 실험이 있다고 가정합니다. 아래 그래프는 이 예측의 절대 오차를 나타냅니다.
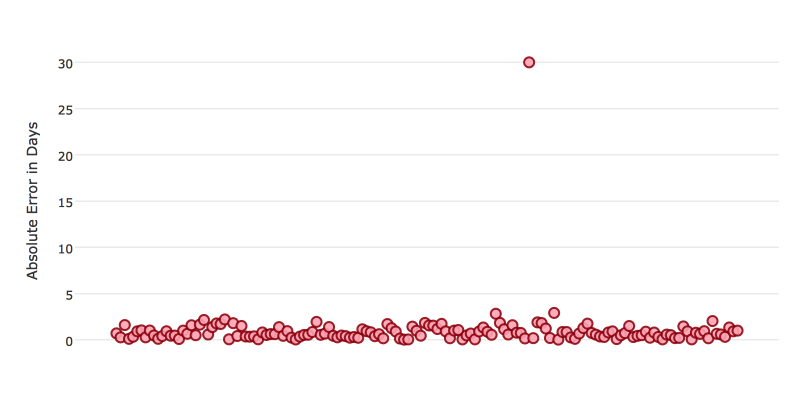
일반적으로 해당 모델은 아주 효과적이며 약 70%는 절대 오차가 1일 미만입니다. 그러나 모델의 성능이 저조한 경우가 있으며 이 경우에는 예측이 30일이나 차이가 났습니다.
이러한 경우는 outliers에 민감한 scorer에 더 높은 벌점을 부과합니다. 일반적으로 매우 정확한 예측을 달성하여 이러한 성능이 낮은 outliers가 크게 중요하지 않은 경우 outliers에 대해 강건한 scorer를 선택합니다. 이는 scorer MSE 및 RMSE 의 동작에 반영됩니다.
MSE |
RMSE |
|
|---|---|---|
Outlier |
0.99 |
2.64 |
Outlier 없음 |
0.80 |
1.0 |
오차 데이터에서 RMSE 및 MSE 를 계산하면, RMSE 가 MSE 보다 두 배 이상 큽니다. RMSE 는 outliers에 민감하기 때문입니다. 계산에서 outliers 레코드 하나를 제거하면 RMSE 가 크게 감소합니다.
성능 단위
다양한 scorer는 Driverless AI 실험의 성능을 여러 단위로 나타냅니다. 이 섹션에서는 목푯값이 이벤트 발생까지의 일수를 예측하는 이전의 예를 계속 설명합니다. 가능한 몇 가지 성능 단위는 다음과 같습니다.
목표값과 동일: scorer의 단위가 일수(day)임.
예: MAE = 5는 모델 예측이 평균 5일 차이나는 것을 의미합니다.
목표값의 백분율: scorer의 단위가 일수(day)의 백분율입니다.
예: MAPE = 10%는 모델 예측이 평균 10% 차이나는 것을 의미합니다.
목표값의 제곱: scorer의 단위가 일수(day) 제곱입니다.
예: MSE = 25는 모델 예측이 평균 5일 차이나는 것을 의미합니다 (25의 제곱근 = 5).
비교
메트릭 |
단위 |
Outliers에 대한 민감도 |
팁 |
|---|---|---|---|
R2 |
0에서 1 사이 |
아니요 |
0과 1 사이의 성능을 원하는 경우 사용 |
MSE |
목푯값의 제곱 |
예 |
|
RMSE |
목푯값과 동일 |
예 |
|
RMSLE |
목푯값의 로그 |
예 |
|
RMSPE |
목푯값의 백분율 |
예 |
목푯값이 여러 척도로 되어 있을 때 사용 |
MAE |
목푯값과 동일 |
아니요 |
|
MAPE |
목푯값의 백분율 |
아니요 |
목푯값이 여러 척도로 되어 있을 때 사용 |
SMAPE |
목푯값의 백분율을 2로 나눔 |
아니요 |
목푯값이 0에 가까울 때 사용 |
scorer 모범 사례 - 분류¶
분류 문제에 사용할 스코어러를 결정할 때는 다음을 고려합니다.
scorer로 예측된 확률 또는 해당 확률이 변환되는 클래스 중 어느 것을 평가할 것인가?
데이터가 불균형한가?
Scorer Evaluates Probabilities or Classes
Driverless AI 모델의 최종 출력은 레코드가 특정 클래스에 있을 것으로 예측되는 확률입니다. 선택한 scorer는 확률이 얼마나 정확한지 또는 해당 확률에서 할당된 클래스가 얼마나 정확한지 평가합니다.
이 선택은 Driverless AI 모델의 사용에 좌우됩니다. 확률을 사용하고 싶은지, 또는 그러한 확률을 클래스로 변환하고 싶은지에 따라 다릅니다. 예를 들어, 고객이 이탈할 가능성을 예측하는 경우 예측된 확률을 이탈할 고객과 이탈하지 않을 고객의 고유한 클래스로 전환할 수 있습니다. 예상되는 수익 손실을 예측하는 경우 예측된 확률을 대신 사용합니다(고객의 이탈 * 값의 예측 확률).
사용 사례에 각 레코드에 할당된 클래스가 필요한 경우, 레코드를 얼마나 잘 분류하는지에 따라 모델 성능을 평가하는 scorer를 선택합니다. 사용 사례에서 확률을 사용하는 경우 예측 확률을 기반으로 모델 성능을 평가하는 scorer를 선택합니다.
불균형 데이터에 대한 강건성
특정한 사용 사례에서는 긍정적 클래스가 매우 희귀합니다. 이러한 경우 일부 scorer가 잘못 이해될 수 있습니다. 예를 들어, 레코드의 99%가 Class = No 인 경우, 항상 No 를 예측하는 모델의 정확도는 99%가 됩니다.
이러한 사용 사례의 경우, True Negative를 포함하지 않거나 AUCPR 또는 MCC와 같은 True Negative의 상대적 크기를 고려하는 메트릭을 선택하는 것이 가장 좋습니다.
비교
메트릭 |
평가 기반 |
팁 |
|---|---|---|
MCC |
클래스 |
모든 클래스에 동일한 가중치 부여 |
F1 |
클래스 |
정밀도와 재현율에 동일한 가중치 부여 |
F0.5 |
클래스 |
정밀도에 높은 가중치, 재현율에 낮은 가중치 부여 |
F2 |
클래스 |
재현율에 높은 가중치, 정밀도에 낮은 가중치 부여 |
Accuracy |
클래스 |
높은 해석력 |
Logloss |
확률 |
확률 최적화 |
AUC |
클래스 |
예측 정렬 순서 최적화 |
AUCPR |
클래스 |
불균형 데이터에 적합함 |