Using models
Interact with or create new models.
Train
Train a model based on your annotation sets. Training models is the Document AI job that consumes the most time.
- Select the model type. One of:
- Page Classification - requires the annotation set to have the class and text file attributes
- Token Labeling - requires the annotation set to have the label and text file attributes
- Select the annotation set you want to train the model
- Select your base model. One of:
- layoutLM-base: (default) takes document layout information into account for modeling. Useful for documents that have rich visual features (e.g. invoices, supply chain docs, ID cards)
- deberta-V3-base: current SOTA model in English NLP field. Useful for plain documents (e.g. legal documents)
- multilingual-deberta-V3-base: multilingual version of the deberta-V3-base model
- Toggle whether you want to define the hyperparameters
- Provide a name for the resulting model
- (Optional) Provide a description of the model
- Toggle whether you want to Evaluate the model
- Provide a name for the Prediction Annotation set
- Select the Evaluation Annotation set
- Click Train to build the model
The model will appear on the Models page when it is finished. If you provided a validation set to build your model, you will also be able to access the accuracy of your model. You view the accuracy of your model on the prediction annotation set which is generated after your model is built. The prediction annotation set can be accessed from the Annotation sets page.
Setting your hyperparameters
You can use the default hyperparameters provided by the Document AI - Publisher UI or you can set your own. To set your own hyperparameters, toggle Use Default Hyperparameters off on the train model panel. These hyperparameters are used to fine tune the internal model on user-provided documents.
Batch size
The batch size is a hyperparameter that defines the number of samples to work through before updating the model parameters. The batch size, or global training batch size, defines the number of documents (with their bounding box coordinates) that are passed over to the processing device (with CPUs or GPUs) at a time. If more than one GPU is available, then per_device_batch_size is determined by dividing the batch size by the number of GPUs.
Smaller batch sizes take longer to run. It takes a long time to reach the optimal solution, but it may converge faster to a good enough solution. The model starts learning with a small number of documents which prevents overfitting on the training dataset because the model only sees a small subset of data at a time. This will generalize well on the test set. For smaller training sizes (tens or hundreds of documents), we recommend using a lower batch size.
Large batch sizes reduce the training time of the model but risk the result of poor generalization or slow model convergence. These can also result in Out of Memory (OOM) errors. For larger training sizes (thousands of documents), we recommend using a slightly larger batch size to cut down on training time.
The default value for batch size is set to 4.
Epochs
An epoch is the hyperparameter that defines the number of times that the learning algorithm works through the entire training dataset. An epoch is defined as one pass over all the training documents.
Increasing the number of epochs results in the model going from underfitting, to optimal fitting, to overfitting on the training data. A good number of epochs helps in reaching the optimal fit.
The default value for epochs is set to 25.
Learning rate
The learning rate hyperparameter sets the learning rate for the AdamW optimizer.
The default value of 5e-5 works well for most models. Deberta models for page classification tasks tend to achieve better results using a lower rate (for example, 2e-5).
Understanding accuracy
You receive accuracy information when you build a model using an evaluation set. To view the accuracy panel, navigate to the Annotation sets page. You can see the new prediction annotation set on the top row. It will have a quality score, which is the f1-score of the model that was applied to the dataset. Click Info on the prediction annotation set that was built with your model.
Click Accuracy located below the description box. You can either scroll through the accuracy results or click Expand for a larger pop-out of the accuracy panel. You can also download the results of the accuracy panel in a JSON file by clicking Download on the accuracy panel.
Accessing top N accuracy
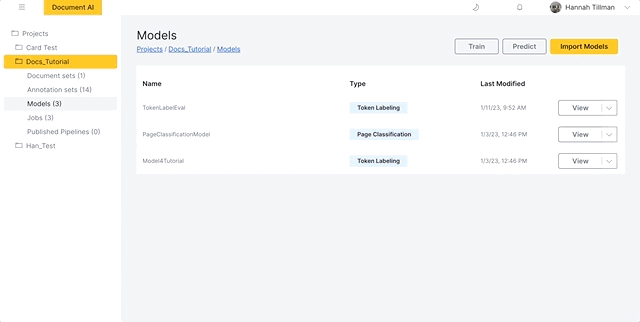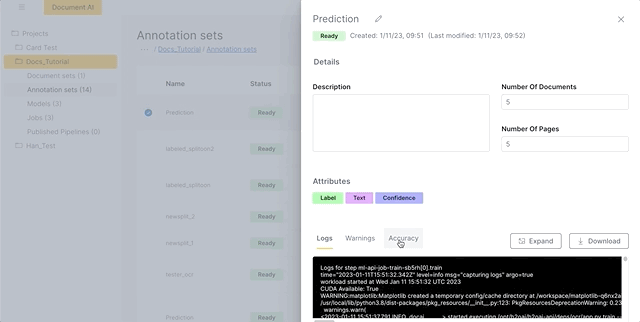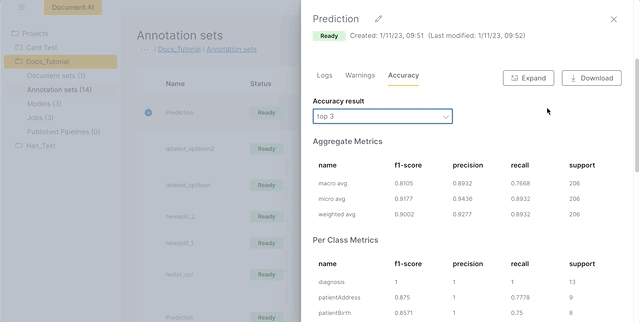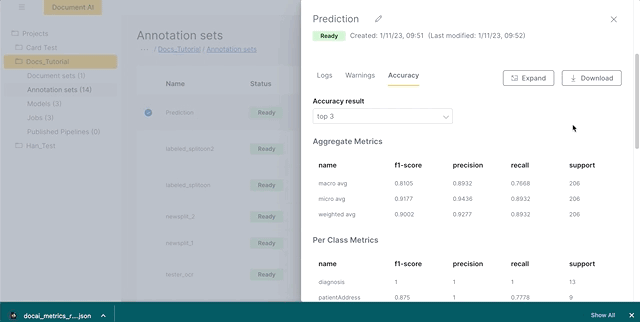
The accuracy panel by default shows you the results for all of the data. To view the top N accuracy results, click the Accuracy result dropdown and select the top N accuracy you want.
Accuracy metrics
Three types of metrics are displayed on the accuracy panel: aggregate metrics, per class metrics, and the class confusion matrix.
- Aggregate metrics measure the accuracy of the entire dataset using the f1-score, precision, recall, and support measures.
- Per class metrics measure the accuracy of one class versus the rest of the datapoints in the dataset using the f1-score, precision, recall, and support measures.
- The class confusion matrix provides a tabular visualization of the model predictions (columns) versus the actual values (rows) for all the classes.
The accuracy panel differs between page classification models and token labeling models. For page classification models, the accuracy panel shows the metrics over different file attributes, and includes macro avg and weighted avg values for the aggregate metrics. For token labeling models, the accuracy panel shows the metrics over different region attributes, and includes macro avg, micro avg, and weighted avg values for the aggregate metrics.
Predict
Predict on an annotation set using a successfully built model.
- Select the model to use for predictions
- Provide a name for the prediction set
- (Optional) Provide a description for the prediction set
- Select the Evaluation Annotation set
- Click Predict to retrieve the predictions
Your predictions will be available on the Annotation sets page when the job is finished running.
Import Models
Import a previously built model that you have saved to your local computer.
- Provide a name for the imported model
- (Optional) Add a description
- Drag and drop the file or browse your local files for the zipped model file
- Click Import
Interacting with a model
Each trained model has an Info button at the end of the row. Clicking Info will give you the details of your model (e.g. the description or base model). You can also find the logs for your model here. To see the full log, click Expand. You can also download the log by clicking Download. If you trained your model with a validation set, you can also access the accuracy of that model.
The drop-down arrow next to the Info button gives you the option to either rename, export, or delete your model.
Rename
Rename the model and provide a new description.
Export
Export a zip file of the model to your local computer.
Delete
Delete the model. You will be prompted to acknowledge that the act of deletion is irreversible before you can delete your model
- Submit and view feedback for this page
- Send feedback about H2O Document AI to cloud-feedback@h2o.ai