Handling PII in h2oGPTe
Overview
Protecting personally identifiable information (PII) is essential for the safe use of generative AI systems. Enterprise h2oGPTe includes configurable features for detecting and handling PII. These capabilities are designed for organizations working with sensitive data and can be customized to fit specific use cases.
Options for sanitization
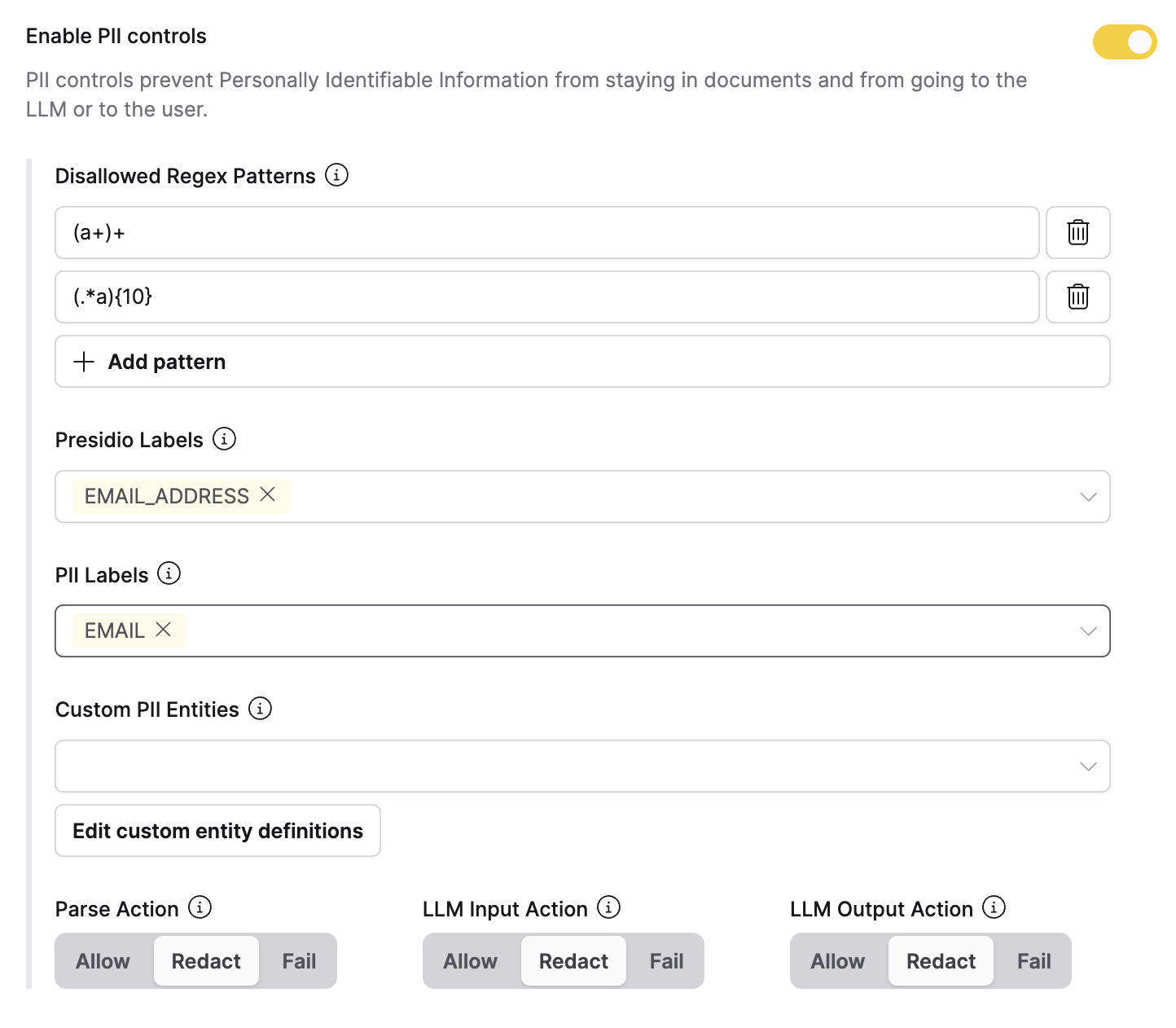
When PII is detected, h2oGPTe supports the following actions:
- Take no action (allow pass-through): PII is identified but left in place. This is useful for internal or testing scenarios, or when full transparency is required.
- Redact or sanitize: Sensitive parts are replaced with the detected type of PII (for example, with [PHONENUMBER] or [XXXXX]) before being used anywhere in the system.
- Fail: The action is halted and a failure is returned. Use this option where strict, fail-safe privacy controls are required.
You can set the appropriate action based on risk tolerance, user role, or business process at the Collection level to apply to all specific types of PII in that Collection.
![]()
Where PII redaction happens
PII detection and redaction can occur at the following stages:
- Document ingestion: When a document is added to a Collection or chat session, the system uses the Collection's settings to detect and handle PII. This applies to the original document as well as to extracted or embedded data.
When documents are added to the vector database (used for retrieval-augmented generation, or RAG), PII can be detected and sanitized before storage.note
- When choosing Redact during document ingestion for audio files, the PII is only sanitized after it has been transcribed.
- PII detection only applies to documents ingested for RAG, not to files uploaded for agent-only use.
- On user inputs: When a user interacts with an LLM or agent, all queries can be checked and handled for PII before reaching the model. This applies to direct user inputs and to the system prompt.
- On model outputs: Before an LLM output is displayed or sent to users, PII can be detected and handled.
You can configure PII handling independently for each stage, depending on your compliance and privacy requirements.

PII detection methods
h2oGPTe supports four different methods to find PII in your data. Each method has unique advantages and is customizable depending on your use case. It is common to use multiple methods in a single Collection.
- Regular expressions (regex): Detects PII using predefined patterns or templates. Suitable for standardized formats such as email addresses or Social Security numbers.
- Presidio labels (SpaCy/Presidio-style): Uses Microsoft's Presidio engine to identify entities such as
PERSON,EMAIL_ADDRESS, orLOCATIONusing a mix of rules and natural language processing models. This method is useful for free-text data where PII appears in various forms. Language is auto-detected — supported languages include English, Spanish, French, German, Chinese, and Portuguese. - ModernBERT-based custom model: A transformer model fine-tuned by H2O.ai for identifying PII in complex or unstructured text. This method can be retrained to support different languages or domains.
note
This model is regularly updated to improve its performance. Recent enhancements have increased the accuracy and reliability of PII detection, with particular improvements for identifying entities like phone numbers.
- Custom PII detection (LLM-based): Use an LLM to detect and redact user-defined personal-information labels. You can define custom entities (for example,
SSNorDOB)(applied for both tabular and non‑tabular documents via appropriate flows) to identify and edit those entities in your documents.
Note: This feature depends on model predictions, so validate results and follow your organization's privacy and compliance policies when using external models.
Each method can be tailored based on your data and privacy needs. For example, you can tune regex patterns, update your list of Presidio labels, retrain the ModernBERT model, or enable custom PII labels for LLM-based detection.
Supported PII entity types
h2oGPTe can detect and handle a wide range of PII entities using two different detection engines:
PII labels (ModernBERT model)
Sensitive entities (may pose a high risk if exposed):
- ACCOUNTNUMBER - Bank account numbers
- CREDITCARDNUMBER - Credit card numbers
- DRIVERLICENSENUM - Driver's license numbers
- IBAN - International Bank Account Numbers
- IDCARDNUM - National ID card numbers
- PASSPORTNUM - Passport numbers
- PHONEIMEI - Mobile device IMEI numbers
- SOCIALNUM - Social Security Numbers
Non-sensitive entities (may require protection):
- AGE - Age information
- CITY - City names
- EMAIL - Email addresses
- TELEPHONENUM - Phone numbers
- STREET - Street addresses
- COMPANY_NAME - Organization names
- GIVENNAME - First names
- SURNAME - Last names
- USERNAME - User names
- IPV4 / IPV6 - IP addresses
- URL - Website URLs
- ZIPCODE - Postal codes
Presidio labels (Microsoft Presidio engine)
Sensitive Presidio entities
Global
- CREDIT_CARD - Credit card numbers
- IBAN_CODE - International Bank Account Numbers
United States
- US_BANK_NUMBER - US bank account numbers
- US_DRIVER_LICENSE - US driver's license numbers
- US_ITIN - US Individual Taxpayer Identification Numbers
- US_PASSPORT - US passport numbers
- US_SSN - US Social Security Numbers
- ABA_ROUTING_NUMBER - ABA routing transit numbers
- US_MBI - US Medicare Beneficiary Identifiers
- US_NPI - US National Provider Identifiers
United Kingdom
- UK_NHS - UK National Health Service numbers
- UK_NINO - UK National Insurance numbers
Brazil
- BR_CPF - Brazilian individual taxpayer ID (Cadastro de Pessoas Físicas)
- BR_CNPJ - Brazilian company tax ID (Cadastro Nacional da Pessoa Jurídica)
- BR_RG - Brazilian national identity card number (Registro Geral)
Spain
- ES_NIF - Spanish tax identification number
- ES_NIE - Spanish foreigner identification number
Italy
- IT_FISCAL_CODE - Italian fiscal code
- IT_DRIVER_LICENSE - Italian driver's license numbers
- IT_VAT_CODE - Italian VAT code
- IT_PASSPORT - Italian passport numbers
- IT_IDENTITY_CARD - Italian identity card numbers
Other countries
- PL_PESEL - Polish national identification number
- SG_NRIC_FIN - Singapore National Registration Identity Card
- AU_TFN - Australian Tax File Number
- AU_MEDICARE - Australian Medicare number
- IN_PAN - Indian Permanent Account Number
- IN_AADHAAR - Indian Aadhaar number
Non-sensitive Presidio entities
- CRYPTO - Cryptocurrency wallet numbers
- DATE_TIME - Absolute or relative dates, periods, or times
- EMAIL_ADDRESS - Email addresses
- IP_ADDRESS - Internet Protocol addresses (IPv4 or IPv6)
- NRP - Nationality, religious, or political group affiliations
- LOCATION - Geographic locations
- PERSON - Full person names
- PHONE_NUMBER - Telephone numbers
- MEDICAL_LICENSE - Medical license numbers
Configuration options
Collection-level configuration
PII settings can be configured at the Collection level through the UI or API:
- Through the UI: Navigate to your Collection settings and select Enable PII controls.
- Through the API: Include
guardrails_settingsin your Collection creation or update requests.
System-level configuration
Administrators can set default PII policies system-wide through environment variables and Docker configuration. The default setting in most environments is for PII detection to be disabled.
API configuration examples
Using the Python client
from h2ogpte import H2OGPTE
client = H2OGPTE(
address="https://h2ogpte.genai.h2o.ai",
api_key='sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX',
)
# Create collection with PII settings
collection_id = client.create_collection(
name="My Collection with PII Settings",
description="Collection with custom PII detection settings",
collection_settings={
"guardrails_settings": {
"pii_detection_parse_action": "redact", # "allow", "redact", or "fail"
"pii_detection_llm_input_action": "redact",
"pii_detection_llm_output_action": "redact"
}
}
)
This Python client usage pattern with create_collection and collection_settings is documented in the official h2oGPTe Python Client Tutorial 2, which demonstrates creating Collections with guardrails settings.
Using REST API
curl -X POST 'https://h2ogpte.genai.h2o.ai/api/v1/collections' \
-H 'Authorization: Bearer your-api-key' \
-H 'Content-Type: application/json' \
-d '{
"name": "Sensitive Documents",
"description": "Collection with PII protection",
"collection_settings": {
"guardrails_settings": {
"pii_detection_parse_action": "redact",
"pii_detection_llm_input_action": "redact",
"pii_detection_llm_output_action": "redact",
"pii_labels_to_flag": ["SOCIALNUM", "CREDITCARDNUMBER"],
"presidio_labels_to_flag": ["US_SSN", "CREDIT_CARD"]
}
}
}'
Best practices
Choose the right detection method
See PII detection methods for detailed descriptions.
It's common to use multiple methods in a single Collection for comprehensive coverage.
Set appropriate actions
See Options for sanitization for detailed action descriptions. Choose Redact for most scenarios.
Performance considerations
- Regex, Presidio, and ModernBERT detection methods are fast and add minimal processing time to document ingestion and chat responses.
- Test with your representative data to balance security and performance for your specific use case.
Next steps
- Create a Collection with PII settings
- Tutorial 7: Guardrails and PII for hands-on setup
- REST API reference for complete API documentation
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai